
 赛灵思FPGA卷积神经网络云中的机器学习.docx
赛灵思FPGA卷积神经网络云中的机器学习.docx
《赛灵思FPGA卷积神经网络云中的机器学习.docx》由会员分享,可在线阅读,更多相关《赛灵思FPGA卷积神经网络云中的机器学习.docx(5页珍藏版)》请在第一文库网上搜索。
1、赛灵思FPGA卷积神经网络,云中的机器学习凭借出色的性能和功耗指标,赛灵思FPGA成为设计人员构建卷积神经网组的首选。新的软件工具可简化实现工作。人工智能正在经历一场变革,这要得益于机迷学工的快速进步。在机器学习领域,人们正对一类名为“深度学习”篁法产生浓厚的兴趣,因为这类算法具有出色的大数据集性能。在深度学习中,机器可以在监督或不受监督的方式下从大量数据中学习一项任务。大规模监督式学习已经在图像识别和语音识别等任务中取得巨大成功。深度学习技术使用大量已知数据找到一组权重和偏差值,以匹配预期结果。这个过程被称为训练,并会产生大型模式。这激励工师倾向于利用专用硬件(例如GPU)进行训练和分类。随
2、着数据量的进一步增加,机器学习将转移到云。大型机器学习模式实现在云端的CPUo尽管GPU对深度学习算法而言在性能方面是一种更好的选择,但功耗要求之高使其只能用于高性能计算集群。因此,亟需一种能够加速算法又不会显著增加功耗的处理平台。在这样的背景下,FPGA似乎是一种理想的选择,其固有特性有助于在低功耗条件下轻松启动众多并行过程。让我们来详细了解一下如何在赛灵思FPGA上实现卷积神经网络(CNN)0CNN是一类深度神经网络,在处理大规模图像识别任务以及与机器学习类似的其他问题方面已大获成功。在当前案例中,针对在FPGA上实现CNN做一个可行性研究,看一下FPGA是否适用于解决大规模机器学习问题。
3、卷积神经网络是一种深度神经网络(DNN),工程师最近开始将该技术用于各种识别任务。图像识别、语音识别和自然语言处理是CNN比较常见的几大应用。什么是卷积神经网络?卷积神经网络是一种深度神经网络(DNN),工程师最近开始将该技术用于各种识别任务。图像识别、语音识别和自然语言处理是CNN比较常见的几大应用。2012年,A1exKrishevsky与来自多伦多大学(UniversityofToronto)的其他研究人员1提出了一种基于CNN的深度架构,赢得了当年的Imagenet大规模视觉识别挑战”奖。他们的模型与竞争对手以及之前几年的模型相比在识别性能方面取得了实质性的提升。自此,A1exNet成
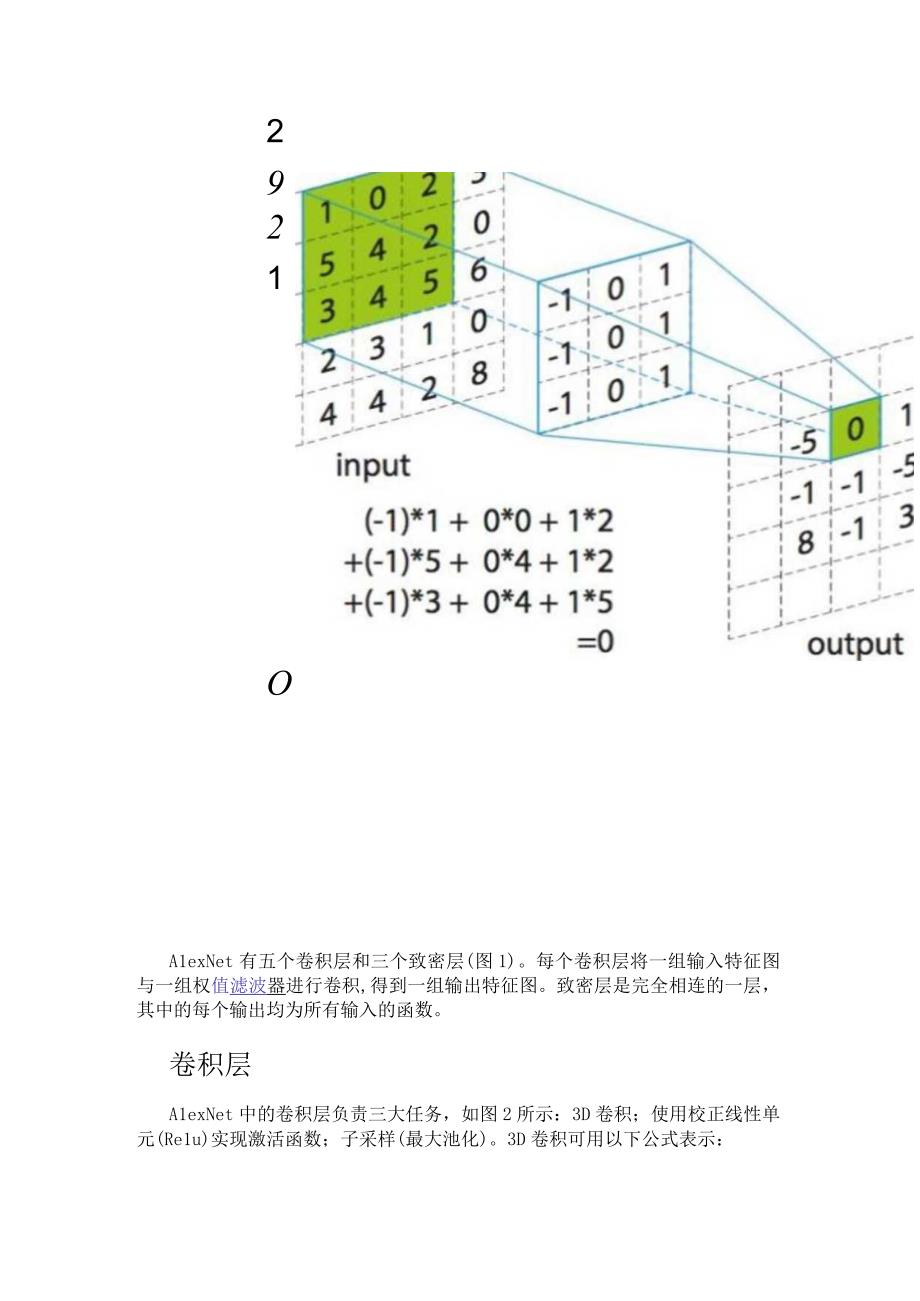
4、为了所有图像识别任务中的对比基准。2921OA1exNet有五个卷积层和三个致密层(图1)。每个卷积层将一组输入特征图与一组权值滤波器进行卷积,得到一组输出特征图。致密层是完全相连的一层,其中的每个输出均为所有输入的函数。卷积层A1exNet中的卷积层负责三大任务,如图2所示:3D卷积;使用校正线性单元(Re1u)实现激活函数;子采样(最大池化)。3D卷积可用以下公式表示:其中Y(m,x,y)是输出特征图m位置(x,y)处的卷积输出,S是(x,y)周围的局部邻域,W是卷积滤波器组,X(n,x,y)是从输入特征图n上的像素位置(x,y)获得的卷积运算的输入。所用的激活函数是一个校正线性单元,可执




- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 赛灵思 FPGA 卷积 神经网络 中的 机器 学习
 第一文库网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
第一文库网所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 调和油系列产品项目可行性研究报告.doc
调和油系列产品项目可行性研究报告.doc
-
三相调压器项目可行性研究报告.doc
-
可行性分析报告设立XX基金管理公司项目可行性分析报告.doc
-
丁硅料项目可行性研究报告.doc
-
二手车交易市场建设项目可行性研究报告.doc
-
二手车交易市场项目可行性研究报告.doc
-
二万头商品猪项目可行性研究报告大纲2.doc
-
二氢松油醇项目可行性研究报告.doc
-
二氧化钛项目可行性研究报告.doc
-
二位五通电磁换向阀项目可行性研究报告.doc
-
二聚酸项目可行性研究报告.doc
-
从化项目可行性报告XXXX329.doc
-
二氧化碳回收项目可行性研究报告.doc
-
水性油墨工程技术研发中心项目可行性研究报告.doc
-
水杀菌消毒项目可行性研究报告.doc
-
水稻种植及加工产业化项目可行性报告.docx
-
水暖五金配件项目可行性研究报告.doc
-
汽车行业-汽车教学整车模型项目可行性研究报告.doc
-
汽车行业-汽车电机零部件项目可行性研究报告.doc
-
汽车行业-汽车空调压缩机支架项目可行性研究报告.doc
-
汽车行业-汽车轮钢项目可行性研究报告摩森咨询·专业编写可行性.doc
-
水果筛选项目可行性研究报告.doc
-
水质改良剂项目可行性研究报告.doc
-
汽车行业-汽车空调电器总成项目可行性研究报告.doc
-
汽车行业-汽车钢卷项目可行性研究报告.doc
-
水泥厂项目可行性研究报告.docx
-
江苏省某幼儿园学校配套停车场项目建议书(代可行性研究报告).docx
-
水泥预制件墙板项目可行性研究报告.doc
-
江西省金韵生态农业示范园建设项目可行性研究报告页(1).docx
-
汽车行业-汽车美容护理用品项目可行性研究报告.doc
-
汽车行业-汽车轮胎套筒项目可行性研究报告.doc
-
汽车行业-汽车阀门项目可行性研究报告.doc
-
市政协常委工作会议结束讲话.docx
-
市水利局关于开展“明确新目标、提升新境界、争创新业绩”建设国际化大都市主题教育活动的实施方案.docx
-
市老干部局学习贯彻落实《关于加强新时代离退休干部党的建设工作的意见》情况汇报.docx
-
市鞭炮烟花管理局创先争优活动公开承诺书.docx
-
师生电子竞技友谊对抗英雄剑舞谁与争锋?.docx
-
常用关联词语.docx
-
干法赤泥堆场库容.docx
-
市司法局工作评议动员会讲话.docx
-
市场监管总局办公厅关于特殊医学用途配方食品变更注册后产品配方和标签更替问题的复函市监特食函〔2020〕348号.docx
-
市委副书记在2022年全市项目建设动员大会上的讲话范文.docx
-
市政协副主席三严三实严以修身专题研讨发言.docx
-
市民对“错峰限行”政策感受和优化替代政策期盼调查问卷.docx
-
市纪委书记在2022年上半年纪检监察工作总结会议上的讲话、税务局2022年上半年全面从严治党一体化综合监督工作总结2篇.docx
-
市长在全市疫情防控专题会上的讲话发言.docx
-
师德承诺书.docx
-
常用个人简历实用模板.docx
-
市发展改革委年度工作要点.docx
-
干法赤泥堆场分区.docx
-
市场活动方案.docx

